kafka:消费者rebalance简析
kafka一个主题的一个分区在同一个group中只能被一个消费者消费,如果不是同一个group中的消费者可以同时消费。为了实现这个功能kafka需要管理和分配group中的消费分区。这一大块功能属于coordinator。
关键字解释
coordinator
- Consumer Group用group.id(String)作为全局唯一标识符
- 每个Group可以有零个、一个或多个Consumer Client
- 每个Group可以管理零个、一个或多个Topic
- Group下每个Consumer Client可同时订阅Topic的一个或多个Partition
- Group下同一个Partition只能被一个Client订阅,多Group下的Client订阅不受影响;因为如果一个Partition有多个Consumer,那么每个Consumer在该Partition上的Offset很可能会不一致,这样会导致在Rebalance后赋值处理的Client的消费起点发生混乱;与此同时,这种场景也不符合Kafka中Partition消息消费的一致性;因此在同一Group下一个Partition只能对应一个Consumer Client。
rebalance
它本质上是一种协议,规定了一个 Consumer Group 下的所有 consumer 如何达成一致,来分配订阅 Topic 的每个分区。例如:某 Group 下有 20 个 consumer 实例,它订阅了一个具有 100 个 partition 的 Topic 。正常情况下,kafka 会为每个 Consumer 平均的分配 5 个分区。这个分配的过程就是 Rebalance。
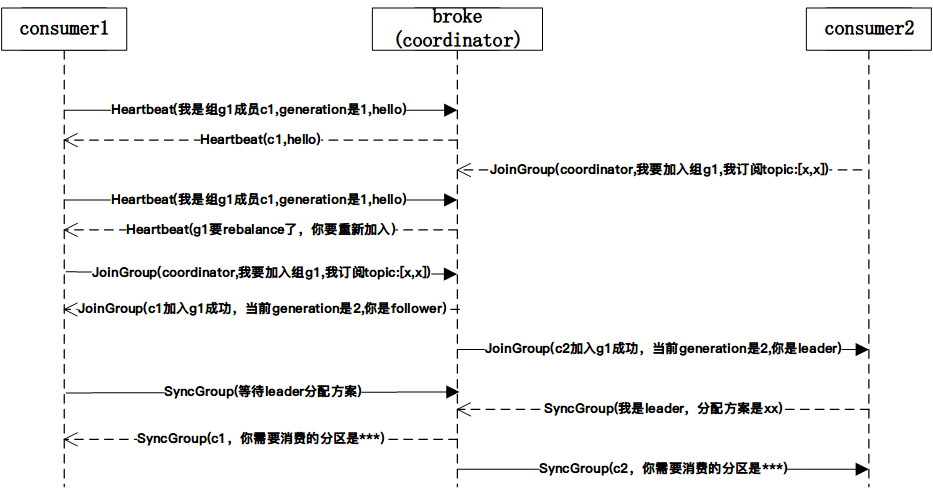
需要注意的是,rebalance过程中group内的所有consumer会停止消费,非常影响kafka的消费性能,所以需要尽量避免rebalance的发生。
源码解析
消费者拉取消息过程
消费者拉取消息是通过KafkaConsumer.poll(),这也是rebalance过程的一个入口。
前面的调用链就简化一下:
KafkaConsumer.poll(final Duration timeout)
-> KafkaConsumer.poll(final Timer timer, final boolean includeMetadataInTimeout)
-> KafkaConsumer.updateAssignmentMetadataIfNeeded
-> coordinator.poll
1 | public ConsumerRecords<K, V> poll(final Duration timeout) { |
在KafkaConsumer.poll中会执行updateAssignmentMetadataIfNeeded方法,在这个方法里执行了coordinator的poll方法。
1 | boolean updateAssignmentMetadataIfNeeded(final Timer timer) { |
ConsumerCoordinator.poll
rebalance的核心是ensureActiveGroup方法,在ensureActiveGroup中会发起JoinGroup请求和SyncGroup请求。
1 | public boolean poll(Timer timer) { |
invokeCompletedOffsetCommitCallbacks
1 | void invokeCompletedOffsetCommitCallbacks() { |
pollHeartbeat
1 | protected synchronized void pollHeartbeat(long now) { |
确保coordinator服务处于ready状态ensureCoordinatorReady
1 | protected synchronized boolean ensureCoordinatorReady(final Timer timer) { |
查找Coordinator节点1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25protected synchronized RequestFuture<Void> lookupCoordinator() {
if (findCoordinatorFuture == null) {
// find a node to ask about the coordinator
// 选择负载最小的节点
Node node = this.client.leastLoadedNode();
if (node == null) {
log.debug("No broker available to send FindCoordinator request");
return RequestFuture.noBrokersAvailable();
} else
findCoordinatorFuture = sendFindCoordinatorRequest(node);
}
return findCoordinatorFuture;
}
// 发起查找Coordinator节点的请求
private RequestFuture<Void> sendFindCoordinatorRequest(Node node) {
// initiate the group metadata request
log.debug("Sending FindCoordinator request to broker {}", node);
FindCoordinatorRequest.Builder requestBuilder =
new FindCoordinatorRequest.Builder(
new FindCoordinatorRequestData()
.setKeyType(CoordinatorType.GROUP.id())
.setKey(this.rebalanceConfig.groupId));
return client.send(node, requestBuilder)
.compose(new FindCoordinatorResponseHandler());
}
查找Coordinator会先发生一个查找请求到当前负载最小broker节点上,然后broker会计算当前组所属的Coordinator节点是哪个;这个计算逻辑是根据groupId的hash值对__consumer_offset_主题的分区数取余,这个分区所在的broker也就是这个group的Coordinator
Utils.abs(groupId.hashCode) % groupMetadataTopicPartitionCount
这也意味着这个group的所有消息的offset信息都会记录在这个__consumer_offset_主题的这个分区中。
__consumer_offset_主题的默认分区数是50。
needRejoin 是否需要rebalance
1 | public boolean rejoinNeededOrPending() { |
只有auto assign模式的才可能需要,如果订阅的topic list发生变化、订阅的topic的partition发生变化,就需要rejoin,也就是要进行rebalance过程,其实还有个条件会触发,就是当group里有新的consumer加入或者有consumer主动退出或挂掉。
rebalance核心ensureActiveGroup
1 | boolean ensureActiveGroup(final Timer timer) { |
开启心跳线程startHeartbeatThreadIfNeeded
开启单独的心跳处理线程1
2
3
4
5
6private synchronized void startHeartbeatThreadIfNeeded() {
if (heartbeatThread == null) {
heartbeatThread = new HeartbeatThread();
heartbeatThread.start();
}
}
加入组joinGroupIfNeeded
1 | boolean joinGroupIfNeeded(final Timer timer) { |
加入组的前期准备/处理onJoinPrepare
加入组的前期准备/处理1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66protected void onJoinPrepare(int generation, String memberId) {
log.debug("Executing onJoinPrepare with generation {} and memberId {}", generation, memberId);
// commit offsets prior to rebalance if auto-commit enabled
// 开启自动提交则先提交offset
maybeAutoCommitOffsetsSync(time.timer(rebalanceConfig.rebalanceTimeoutMs));
// the generation / member-id can possibly be reset by the heartbeat thread
// upon getting errors or heartbeat timeouts; in this case whatever is previously
// owned partitions would be lost, we should trigger the callback and cleanup the assignment;
// otherwise we can proceed normally and revoke the partitions depending on the protocol,
// and in that case we should only change the assignment AFTER the revoke callback is triggered
// so that users can still access the previously owned partitions to commit offsets etc.
// 错误或心跳超时时,心跳线程可能会重置generation / member-id
// 这个时候清理订阅的主题
Exception exception = null;
final Set<TopicPartition> revokedPartitions;
if (generation == Generation.NO_GENERATION.generationId &&
memberId.equals(Generation.NO_GENERATION.memberId)) {
revokedPartitions = new HashSet<>(subscriptions.assignedPartitions());
if (!revokedPartitions.isEmpty()) {
log.info("Giving away all assigned partitions as lost since generation has been reset," +
"indicating that consumer is no longer part of the group");
exception = invokePartitionsLost(revokedPartitions);
// 清空订阅
subscriptions.assignFromSubscribed(Collections.emptySet());
}
} else {
switch (protocol) {
case EAGER:
// revoke all partitions
revokedPartitions = new HashSet<>(subscriptions.assignedPartitions());
exception = invokePartitionsRevoked(revokedPartitions);
subscriptions.assignFromSubscribed(Collections.emptySet());
break;
case COOPERATIVE:
// only revoke those partitions that are not in the subscription any more.
Set<TopicPartition> ownedPartitions = new HashSet<>(subscriptions.assignedPartitions());
revokedPartitions = ownedPartitions.stream()
.filter(tp -> !subscriptions.subscription().contains(tp.topic()))
.collect(Collectors.toSet());
if (!revokedPartitions.isEmpty()) {
// 执行rebalance监听器回调
exception = invokePartitionsRevoked(revokedPartitions);
ownedPartitions.removeAll(revokedPartitions);
// 清理订阅
subscriptions.assignFromSubscribed(ownedPartitions);
}
break;
}
}
isLeader = false;
// 更新组信息,groupSubscription = Collections.emptySet()
subscriptions.resetGroupSubscription();
if (exception != null) {
throw new KafkaException("User rebalance callback throws an error", exception);
}
}
加入组响应处理JoinGroupResponseHandler
在JoinGroupResponseHandler响应处理器中,根据响应信息判断当前节点是不是leader节点;如果是leader节点则对组内节点分配分区,发起SyncGroup请求将分区结果带给coordinator节点;如果不是leader节点,则发起SyncGroup请求没有分区分配信息。
1 | public void handle(JoinGroupResponse joinResponse, RequestFuture<ByteBuffer> future) { |