zk集群启动QuorumPeerMain解析
入口查看
打开启动脚本zkServer.cmd/zkServer.sh,可以找到以下的内容:1
ZOOMAIN="org.apache.zookeeper.server.quorum.QuorumPeerMain"
可知入口类是org.apache.zookeeper.server.quorum.QuorumPeerMain
QuorumPeerMain解析
类继承关系
1 | .Public |
成员变量
1 | private static final String USAGE = "Usage: QuorumPeerMain configfile"; |
main方法
main方法中new了一个QuorumPeerMain类,然后调用它的initializeAndRun(args)方法,所以的运行内容都在initializeAndRun(args)方法中1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public static void main(String[] args) {
QuorumPeerMain main = new QuorumPeerMain();
try {
main.initializeAndRun(args);
} catch (IllegalArgumentException e) {
LOG.error("Invalid arguments, exiting abnormally", e);
LOG.info(USAGE);
System.err.println(USAGE);
System.exit(2);
} catch (ConfigException e) {
LOG.error("Invalid config, exiting abnormally", e);
System.err.println("Invalid config, exiting abnormally");
System.exit(2);
} catch (Exception e) {
LOG.error("Unexpected exception, exiting abnormally", e);
System.exit(1);
}
LOG.info("Exiting normally");
System.exit(0);
}
初始化与运行initializeAndRun(String[] args)
- 使用QuorumPeerConfig解析命令行参数args;
- 启动定时清理任务DatadirCleanupManager.start();
- 是集群启动则runFromConfig(config);
- 不然走ZooKeeperServerMain.main(args);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22protected void initializeAndRun(String[] args) throws ConfigException, IOException{
QuorumPeerConfig config = new QuorumPeerConfig();
if (args.length == 1) {
config.parse(args[0]);
}
// Start and schedule the the purge task
// 启动定时清理任务
DatadirCleanupManager purgeMgr = new DatadirCleanupManager(config
.getDataDir(), config.getDataLogDir(), config
.getSnapRetainCount(), config.getPurgeInterval());
purgeMgr.start();
// config.servers.size() 判断集群服务器数量
if (args.length == 1 && config.servers.size() > 0) {
runFromConfig(config);
} else {
LOG.warn("Either no config or no quorum defined in config, running "
+ " in standalone mode");
// there is only server in the quorum -- run as standalone
ZooKeeperServerMain.main(args);
}
}
集群启动runFromConfig(QuorumPeerConfig config)
- jmx管理log4j;
- 创建上下文工厂;
- 跟进配置项config配置QuorumPeer;
- 执行quorumPeer的初始化方法 initialize();
- 线程启动 quorumPeer.start();
- 主线程等待quorumPeer线程退出 quorumPeer.join();
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58public void runFromConfig(QuorumPeerConfig config) throws IOException {
try {
// jmx管理log4j
ManagedUtil.registerLog4jMBeans();
} catch (JMException e) {
LOG.warn("Unable to register log4j JMX control", e);
}
LOG.info("Starting quorum peer");
try {
// 服务器上下文工厂,默认实现是NIOServerCnxnFactory,可以通过环境变量zookeeper.serverCnxnFactory设置
// 这个工厂类保存了sessionMap
ServerCnxnFactory cnxnFactory = ServerCnxnFactory.createFactory();
cnxnFactory.configure(config.getClientPortAddress(),
config.getMaxClientCnxns());
quorumPeer = getQuorumPeer();
// 将config配置到quorumPeer
quorumPeer.setQuorumPeers(config.getServers());
quorumPeer.setTxnFactory(new FileTxnSnapLog(
new File(config.getDataLogDir()),
new File(config.getDataDir())));
quorumPeer.setElectionType(config.getElectionAlg());
quorumPeer.setMyid(config.getServerId());
quorumPeer.setTickTime(config.getTickTime());
quorumPeer.setInitLimit(config.getInitLimit());
quorumPeer.setSyncLimit(config.getSyncLimit());
quorumPeer.setQuorumListenOnAllIPs(config.getQuorumListenOnAllIPs());
quorumPeer.setCnxnFactory(cnxnFactory);
quorumPeer.setQuorumVerifier(config.getQuorumVerifier());
quorumPeer.setClientPortAddress(config.getClientPortAddress());
quorumPeer.setMinSessionTimeout(config.getMinSessionTimeout());
quorumPeer.setMaxSessionTimeout(config.getMaxSessionTimeout());
quorumPeer.setZKDatabase(new ZKDatabase(quorumPeer.getTxnFactory()));
quorumPeer.setLearnerType(config.getPeerType());
quorumPeer.setSyncEnabled(config.getSyncEnabled());
// sets quorum sasl authentication configurations
// Simple Authentication and Security Layer,一种用户身份认证机制
quorumPeer.setQuorumSaslEnabled(config.quorumEnableSasl);
if(quorumPeer.isQuorumSaslAuthEnabled()){
quorumPeer.setQuorumServerSaslRequired(config.quorumServerRequireSasl);
quorumPeer.setQuorumLearnerSaslRequired(config.quorumLearnerRequireSasl);
quorumPeer.setQuorumServicePrincipal(config.quorumServicePrincipal);
quorumPeer.setQuorumServerLoginContext(config.quorumServerLoginContext);
quorumPeer.setQuorumLearnerLoginContext(config.quorumLearnerLoginContext);
}
quorumPeer.setQuorumCnxnThreadsSize(config.quorumCnxnThreadsSize);
quorumPeer.initialize();
quorumPeer.start();
quorumPeer.join();
} catch (InterruptedException e) {
// warn, but generally this is ok
LOG.warn("Quorum Peer interrupted", e);
}
}
QuorumPeer 解析
类继承关系
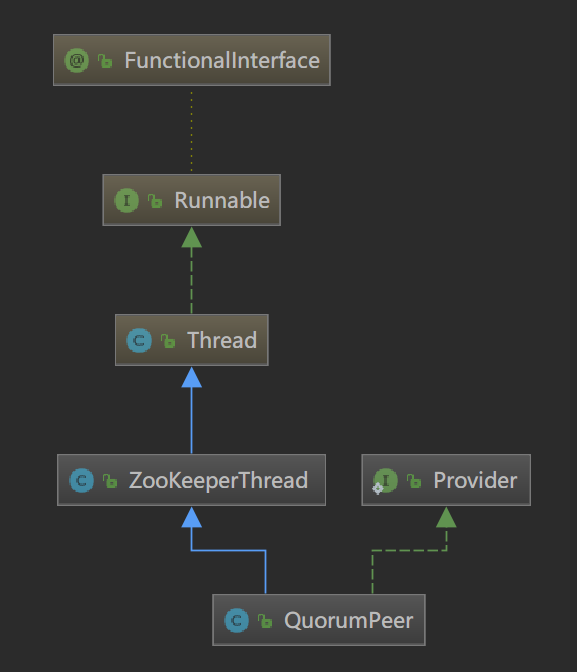
1
public class QuorumPeer extends ZooKeeperThread implements QuorumStats.Provider {...}
成员变量
1 | QuorumBean jmxQuorumBean; |
初始化initialize()
根据是否开启Sasl权限校验初始化QuorumAuthServer和QuorumAuthLearner。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public void initialize() throws SaslException {
// init quorum auth server & learner
// quorumSaslEnableAuth 是否开启权限校验
if (isQuorumSaslAuthEnabled()) {
Set<String> authzHosts = new HashSet<String>();
for (QuorumServer qs : getView().values()) {
authzHosts.add(qs.hostname);
}
authServer = new SaslQuorumAuthServer(isQuorumServerSaslAuthRequired(),
quorumServerLoginContext, authzHosts);
authLearner = new SaslQuorumAuthLearner(isQuorumLearnerSaslAuthRequired(),
quorumServicePrincipal, quorumLearnerLoginContext);
authInitialized = true;
} else {
authServer = new NullQuorumAuthServer();
authLearner = new NullQuorumAuthLearner();
}
}
执行启动流程start()
- 加载硬盘数据到内存;
- 开启数据读写Server;
- 选主;
1
2
3
4
5
6
7
public synchronized void start() {
loadDataBase();
cnxnFactory.start();
startLeaderElection();
super.start();
}
加载硬盘数据到内存 loadDataBase()
1 | private void loadDataBase() { |
开启数据读写服务cnxnFactory.start()
ServerCnxnFactory是作为处理读写的Server,有不同的实现方式。
由上文ServerCnxnFactory cnxnFactory = ServerCnxnFactory.createFactory();可以知道默认实现是NIOServerCnxnFactory,所以参考该类的实现。
public class NIOServerCnxnFactory extends ServerCnxnFactory implements Runnable
NIOServerCnxnFactory实现了Runnable接口,同时内部保存了一个Thread对象,start方法就是执行这个Thread对象的start()。即单独开一个线程实现读写Server。
1 |
|
主要看实现的run()方法。run方法实现了一个NIO的Server,处理连接和读写请求,其中读写请求由NIOServerCnxn的doIO处理。读写请求处理的详细解析放到另一个章节中解析。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54public void run() {
while (!ss.socket().isClosed()) {
try {
selector.select(1000);
Set<SelectionKey> selected;
synchronized (this) {
selected = selector.selectedKeys();
}
ArrayList<SelectionKey> selectedList = new ArrayList<SelectionKey>(
selected);
Collections.shuffle(selectedList);
for (SelectionKey k : selectedList) {
// 处理连接
if ((k.readyOps() & SelectionKey.OP_ACCEPT) != 0) {
SocketChannel sc = ((ServerSocketChannel) k
.channel()).accept();
InetAddress ia = sc.socket().getInetAddress();
int cnxncount = getClientCnxnCount(ia);
if (maxClientCnxns > 0 && cnxncount >= maxClientCnxns){
LOG.warn("Too many connections from " + ia
+ " - max is " + maxClientCnxns );
sc.close();
} else {
LOG.info("Accepted socket connection from "
+ sc.socket().getRemoteSocketAddress());
sc.configureBlocking(false);
SelectionKey sk = sc.register(selector,
SelectionKey.OP_READ);
NIOServerCnxn cnxn = createConnection(sc, sk);
// 这里添加上下文 NIOServerCnxn
sk.attach(cnxn);
addCnxn(cnxn);
}
// 处理读写请求
} else if ((k.readyOps() & (SelectionKey.OP_READ | SelectionKey.OP_WRITE)) != 0) {
NIOServerCnxn c = (NIOServerCnxn) k.attachment();
c.doIO(k);
} else {
if (LOG.isDebugEnabled()) {
LOG.debug("Unexpected ops in select "
+ k.readyOps());
}
}
}
selected.clear();
} catch (RuntimeException e) {
LOG.warn("Ignoring unexpected runtime exception", e);
} catch (Exception e) {
LOG.warn("Ignoring exception", e);
}
}
closeAll();
LOG.info("NIOServerCnxn factory exited run method");
}
初始化选主startLeaderElection()
投票信息对象1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public class Vote {
final private int version;
final private long id; //服务器id
final private long zxid; //服务器当前zxid
final private long electionEpoch;
final private long peerEpoch;
final private ServerState state; //状态,开始选主时为LOOKING
public Vote(long id,
long zxid,
long electionEpoch,
long peerEpoch) {
this.version = 0x0;
this.id = id;
this.zxid = zxid;
this.electionEpoch = electionEpoch;
this.peerEpoch = peerEpoch;
this.state = ServerState.LOOKING;
}
// ...
}
初始化选主
- 生成投票信息对象Vote,包含服务器ID、当前服务器的zxid、CurrentEpoch,且状态为LOOKING;
- 获取当前服务器配置的addr;
- 生成选举算法;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64synchronized public void startLeaderElection() {
try {
// 生成当前节点(服务器)的投票ID
// myid服务器编号,当前发zxid,时间戳
// 此时Vote的服务器状态是ServerState.LOOKING
currentVote = new Vote(myid, getLastLoggedZxid(), getCurrentEpoch());
} catch(IOException e) {
RuntimeException re = new RuntimeException(e.getMessage());
re.setStackTrace(e.getStackTrace());
throw re;
}
// getView().values() 集群中的observer
// 找到当前服务器的addr
for (QuorumServer p : getView().values()) {
if (p.id == myid) {
myQuorumAddr = p.addr;
break;
}
}
if (myQuorumAddr == null) {
throw new RuntimeException("My id " + myid + " not in the peer list");
}
// electionType区分不同的选举算法,默认值为3,可在配置文件中配置
if (electionType == 0) {
try {
udpSocket = new DatagramSocket(myQuorumAddr.getPort());
responder = new ResponderThread();
// 相应请求,LOOKING状态返回服务器id和zxid
responder.start();
} catch (SocketException e) {
throw new RuntimeException(e);
}
}
// 生成选举算法
// 默认值为3:FastLeaderElection,其他算法在3.4版本中已经废弃
this.electionAlg = createElectionAlgorithm(electionType);
}
protected Election createElectionAlgorithm(int electionAlgorithm){
Election le=null;
switch (electionAlgorithm) {
case 0:
le = new LeaderElection(this);
break;
case 1:
le = new AuthFastLeaderElection(this);
break;
case 2:
le = new AuthFastLeaderElection(this, true);
break;
case 3:
qcm = createCnxnManager();
QuorumCnxManager.Listener listener = qcm.listener;
if(listener != null){
listener.start();
le = new FastLeaderElection(this, qcm);
} else {
LOG.error("Null listener when initializing cnx manager");
}
break;
default:
assert false;
}
return le;
}
开始选主super.start()
看一下继承关系
可以发现start()方法其实是Thread类的实现,也就是开启线程。QuorumPeer类继承了ZooKeeperThread并且重写了Thread的run()方法,也就是开启线程执行内容。接下来看QuorumPeer的run()方法。
这个run()方法一直处于运行状态,当服务器状态改变为LOOKING状态,就会执行选主策略的lookForLeader()方法去选主。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
public void run() {
// Thread类的方法,设置线程名
setName("QuorumPeer" + "[myid=" + getId() + "]" +
cnxnFactory.getLocalAddress());
LOG.debug("Starting quorum peer");
// jmx配置
try {
jmxQuorumBean = new QuorumBean(this);
MBeanRegistry.getInstance().register(jmxQuorumBean, null);
// 遍历所有观察者(observer)
for(QuorumServer s: getView().values()){
ZKMBeanInfo p;
// 当前服务器
if (getId() == s.id) {
p = jmxLocalPeerBean = new LocalPeerBean(this);
try {
MBeanRegistry.getInstance().register(p, jmxQuorumBean);
} catch (Exception e) {
LOG.warn("Failed to register with JMX", e);
jmxLocalPeerBean = null;
}
} else {
p = new RemotePeerBean(s);
try {
MBeanRegistry.getInstance().register(p, jmxQuorumBean);
} catch (Exception e) {
LOG.warn("Failed to register with JMX", e);
}
}
}
} catch (Exception e) {
LOG.warn("Failed to register with JMX", e);
jmxQuorumBean = null;
}
try {
/*
* Main loop 主循环,这个循环一直查询服务器状态,当服务器处于LOOKING状态时就会开始选主
*/
while (running) {
switch (getPeerState()) { // state属性记录当前节点的状态
case LOOKING: //LOOKING状态代表要选主
LOG.info("LOOKING");
// 开启只读模式
if (Boolean.getBoolean("readonlymode.enabled")) {
LOG.info("Attempting to start ReadOnlyZooKeeperServer");
// 只读服务
// Create read-only server but don't start it immediately
final ReadOnlyZooKeeperServer roZk = new ReadOnlyZooKeeperServer(
logFactory, this,
new ZooKeeperServer.BasicDataTreeBuilder(),
this.zkDb);
// Instead of starting roZk immediately, wait some grace
// period before we decide we're partitioned.
//
// Thread is used here because otherwise it would require
// changes in each of election strategy classes which is
// unnecessary code coupling.
Thread roZkMgr = new Thread() {
public void run() {
try {
// lower-bound grace period to 2 secs
sleep(Math.max(2000, tickTime));
if (ServerState.LOOKING.equals(getPeerState())) {
roZk.startup();
}
} catch (InterruptedException e) {
LOG.info("Interrupted while attempting to start ReadOnlyZooKeeperServer, not started");
} catch (Exception e) {
LOG.error("FAILED to start ReadOnlyZooKeeperServer", e);
}
}
};
try {
roZkMgr.start();
setBCVote(null);
// 执行在startLeaderElection()中生成的选主策略的lookForLeader()方法
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
LOG.warn("Unexpected exception",e);
setPeerState(ServerState.LOOKING);
} finally {
// If the thread is in the the grace period, interrupt
// to come out of waiting.
roZkMgr.interrupt();
roZk.shutdown();
}
} else {
try {
setBCVote(null);
// 执行在startLeaderElection()中生成的选主策略的lookForLeader()方法
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
setPeerState(ServerState.LOOKING);
}
}
break;
case OBSERVING: // 成为了观察者
try {
LOG.info("OBSERVING");
setObserver(makeObserver(logFactory));
observer.observeLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception",e );
} finally {
observer.shutdown();
setObserver(null);
setPeerState(ServerState.LOOKING);
}
break;
case FOLLOWING:
try {
LOG.info("FOLLOWING");
setFollower(makeFollower(logFactory));
follower.followLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception",e);
} finally {
follower.shutdown();
setFollower(null);
setPeerState(ServerState.LOOKING);
}
break;
case LEADING:
LOG.info("LEADING");
try {
setLeader(makeLeader(logFactory));
leader.lead();
setLeader(null);
} catch (Exception e) {
LOG.warn("Unexpected exception",e);
} finally {
if (leader != null) {
leader.shutdown("Forcing shutdown");
setLeader(null);
}
setPeerState(ServerState.LOOKING);
}
break;
}
}
} finally {
LOG.warn("QuorumPeer main thread exited");
try {
MBeanRegistry.getInstance().unregisterAll();
} catch (Exception e) {
LOG.warn("Failed to unregister with JMX", e);
}
jmxQuorumBean = null;
jmxLocalPeerBean = null;
}
}
选主策略
所有选主策略都实现了Election接口,其中lookForLeader方法用于选主。1
2
3
4public interface Election {
public Vote lookForLeader() throws InterruptedException;
public void shutdown();
}
目前除FastLeaderElection外的选主方式都已经处于废弃状态,所以主要关注FastLeaderElection。
快速选主FastLeaderElection
继承1
public class FastLeaderElection implements Election{...}
在了解选主之前要先了解一下QuorumCnxManager,QuorumCnxManager通过SocketServer实现与其它服务器选主信息交互。
选主消息管理 QuorumCnxManager Socket
QuorumCnxManager代码比较简单就不解析,这里将主要的流程贴一下:
注意:zk为了防止TCP连接重复,要求只能sid高的节点主动连接sid低的节点。
建立socket连接后,因为socket是阻塞的,所以读写都在单独的线程上执行。
FastLeaderElection.WorkerReceiver处理消息
选主lookForLeader()
完整流程图
简略的流程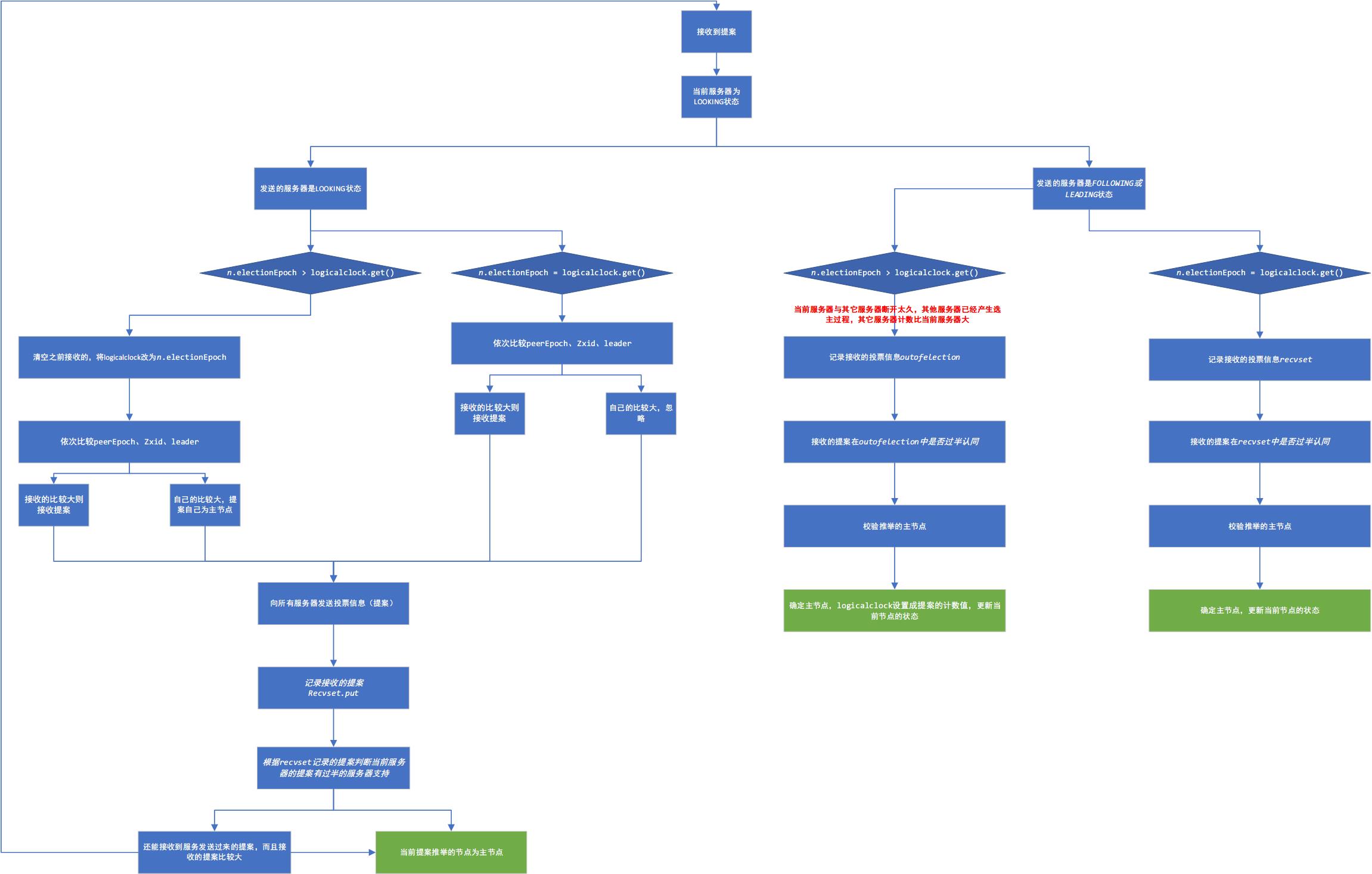
代码解析1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230public Vote lookForLeader() throws InterruptedException {
// jmx
try {
self.jmxLeaderElectionBean = new LeaderElectionBean();
MBeanRegistry.getInstance().register(
self.jmxLeaderElectionBean, self.jmxLocalPeerBean);
} catch (Exception e) {
LOG.warn("Failed to register with JMX", e);
self.jmxLeaderElectionBean = null;
}
if (self.start_fle == 0) {
self.start_fle = Time.currentElapsedTime();
}
try {
// 接收到的Vote
HashMap<Long, Vote> recvset = new HashMap<Long, Vote>();
HashMap<Long, Vote> outofelection = new HashMap<Long, Vote>();
int notTimeout = finalizeWait;
synchronized(this){
// AtomicLong#incrementAndGet
logicalclock.incrementAndGet();
// 更新提案,提案当前服务器为主节点
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
LOG.info("New election. My id = " + self.getId() +
", proposed zxid=0x" + Long.toHexString(proposedZxid));
// 向所有节点发送投票通知,提议当前节点为主节点
sendNotifications();
/*
* Loop in which we exchange notifications until we find a leader
*/
// 循环直到找到主节点
while ((self.getPeerState() == ServerState.LOOKING) &&
(!stop)){
/*
* Remove next notification from queue, times out after 2 times
* the termination time
*/
Notification n = recvqueue.poll(notTimeout,
TimeUnit.MILLISECONDS);
/*
* Sends more notifications if haven't received enough.
* Otherwise processes new notification.
*/
if(n == null){
// 已经发送了,但是没有接收的返回就重新发送
if(manager.haveDelivered()){
sendNotifications();
} else {
manager.connectAll();
}
/*
* Exponential backoff
*/
int tmpTimeOut = notTimeout*2;
notTimeout = (tmpTimeOut < maxNotificationInterval?
tmpTimeOut : maxNotificationInterval);
LOG.info("Notification time out: " + notTimeout);
}
else if(validVoter(n.sid) && validVoter(n.leader)) { // 接收到了响应,validVoter校验响应的服务器是否在集群中
/*
* Only proceed if the vote comes from a replica in the
* voting view for a replica in the voting view.
*/
switch (n.state) {
case LOOKING: // 选主消息
// If notification > current, replace and send messages out
// 每次发消息都会计数logicalclock
// 判断接收到的选举消息是否和发送的消息是同一次
if (n.electionEpoch > logicalclock.get()) {
// 设置当前服务器的计数值为接收到的大的值
logicalclock.set(n.electionEpoch);
recvset.clear();
// totalOrderPredicate 判断推举哪个服务器
// 判断条件curEpoch,curZxid,curId
// 依次比较大小,如果n中的比较大则推举n中发服务器为主节点
if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
} else { // 推举自己为主节点
updateProposal(getInitId(),
getInitLastLoggedZxid(),
getPeerEpoch());
}
// 发送推举的服务器信息
sendNotifications();
} else if (n.electionEpoch < logicalclock.get()) { // 收到的计数值比当前的计数值小
if(LOG.isDebugEnabled()){
LOG.debug("Notification election epoch is smaller than logicalclock. n.electionEpoch = 0x"
+ Long.toHexString(n.electionEpoch)
+ ", logicalclock=0x" + Long.toHexString(logicalclock.get()));
}
break;
// totalOrderPredicate 判断推举哪个服务器
// 判断条件curEpoch,curZxid,curId
// 依次比较大小,如果n中的比较大则推举n中发服务器为主节点
} else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
proposedLeader, proposedZxid, proposedEpoch)) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
sendNotifications();
}
if(LOG.isDebugEnabled()){
LOG.debug("Adding vote: from=" + n.sid +
", proposed leader=" + n.leader +
", proposed zxid=0x" + Long.toHexString(n.zxid) +
", proposed election epoch=0x" + Long.toHexString(n.electionEpoch));
}
// 记录接收到的投票信息
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
// 判断当前服务器支持的提案(proposedLeader)是否已经有过半的服务器支持了
if (termPredicate(recvset,
new Vote(proposedLeader, proposedZxid,
logicalclock.get(), proposedEpoch))) {
// Verify if there is any change in the proposed leader
// 当前已经有半数的服务器同意了提案,看看还能不能接收其他服务器的提案
while((n = recvqueue.poll(finalizeWait,
TimeUnit.MILLISECONDS)) != null){
// 比较接收的提案
if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
proposedLeader, proposedZxid, proposedEpoch)){
recvqueue.put(n);
break; // 提案变更
}
}
// 队列中没有投票信息(提案没有变更,提案变更n是存在值的)
if (n == null) {
// 这里更新状态
// 队列中没有投票信息且当前提案推选的节点为当前服务器ID,则当前节点成为主节点
self.setPeerState((proposedLeader == self.getId()) ?
ServerState.LEADING: learningState());
Vote endVote = new Vote(proposedLeader,
proposedZxid,
logicalclock.get(),
proposedEpoch);
leaveInstance(endVote); //清空recvqueue
return endVote; //返回选主结果
}
}
break;
case OBSERVING:
LOG.debug("Notification from observer: " + n.sid);
break;
case FOLLOWING:
case LEADING: // 其他节点为主节点或者跟随者
// 确定计数值相同,即同一次选举
if(n.electionEpoch == logicalclock.get()){
recvset.put(n.sid, new Vote(n.leader,
n.zxid,
n.electionEpoch,
n.peerEpoch));
// ooePredicate调用了termPredicate判断是否被半数以上的服务器同意
// 并调用checkLeader校验推举的服务器的状态
if(ooePredicate(recvset, outofelection, n)) {
// 设置当前服务器的状态
self.setPeerState((n.leader == self.getId()) ?
ServerState.LEADING: learningState());
Vote endVote = new Vote(n.leader,
n.zxid,
n.electionEpoch,
n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
}
/*
* Before joining an established ensemble, verify
* a majority is following the same leader.
*/
outofelection.put(n.sid, new Vote(n.version,
n.leader,
n.zxid,
n.electionEpoch,
n.peerEpoch,
n.state));
// 走到这步是因为n.electionEpoch > logicalclock.get()
// 即其它服务器已经再次选举了,所以要更新计数logicalclock
if(ooePredicate(outofelection, outofelection, n)) {
synchronized(this){
logicalclock.set(n.electionEpoch); // 更新计数值为新值,新值必然大于旧值
self.setPeerState((n.leader == self.getId()) ?
ServerState.LEADING: learningState());
}
Vote endVote = new Vote(n.leader,
n.zxid,
n.electionEpoch,
n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
break;
default:
LOG.warn("Notification state unrecognized: {} (n.state), {} (n.sid)",
n.state, n.sid);
break;
}
} else {
if (!validVoter(n.leader)) {
LOG.warn("Ignoring notification for non-cluster member sid {} from sid {}", n.leader, n.sid);
}
if (!validVoter(n.sid)) {
LOG.warn("Ignoring notification for sid {} from non-quorum member sid {}", n.leader, n.sid);
}
}
}
return null;
} finally {
try {
if(self.jmxLeaderElectionBean != null){
MBeanRegistry.getInstance().unregister(
self.jmxLeaderElectionBean);
}
} catch (Exception e) {
LOG.warn("Failed to unregister with JMX", e);
}
self.jmxLeaderElectionBean = null;
LOG.debug("Number of connection processing threads: {}",
manager.getConnectionThreadCount());
}
}
思考
updateProposal和getVote函数什么关系
前者根据参数更新提议即(proposedLeader, proposedZxid, proposedEpoch)后者是根据提议(proposedLeader, proposedZxid, proposedEpoch)生成投票可以理解为set和get
getVote()和self.getCurrentVote()的区别是什么
源码中有两种获取vote的形式,这两种的区别是什么getVote()是临时投票,相当于选leader时的提议,会不断变化的self.getCurrentVote()是每次选leader时,最后决定下来的投票,一般都是最终的leader
连续多次等待通知都没有等到,等待通知的时长变化如何
FastLeaderElection#lookForLeader
初始值为200ms,也就是说,只要没等到,就再等double的时间,到400ms,800ms,最终不超过maxNotificationInterval也就是1分钟
FastLeaderElection与QuorumCnxManager关系
选leader时消息的收发依赖QuorumCnxManager,它作为server之间的IO管理器
Vote为什么要peerEpoch字段
peerEpoch:被推举的Leader的epoch。
前面看代码看peerEpoch都是各种set和get,没有发现哪里比较了,最后发现是FastLeaderElection#totalOrderPredicate比较两个vote的大小关系的时候,会先用peerEpoch进行比较
electionEpoch和peerEpoch区别,什么时候会不同?
electionEpoch是选举周期,用于判断是不是同一个选举周期,从0开始累计
peerEpoch是当前周期,用于判断各个server所处的周期,从log中读取currentEpoch
选举leader时,electionEpoch作为大判断条件,要求大家按最新的electionEpoch作为选举周期如果electionEpoch一样,那么再根据currentEpoch和zxid,sid等判断哪个server是最“新”的
参考FastLeaderElection#totalOrderPredicate函数
FastLeaderElection.Messenger.WorkerReceiver#run中,初始化时,认为的leader是哪一个

这里如果是null可是会npe的
ans:值是在这里设置的,初始化时当前投票是投给自己的,QuorumPeer#startLeaderElection,也就是提前调用了
currentVote = new Vote(myid, getLastLoggedZxid(), getCurrentEpoch());
两个vote的全序大小比较规则总结
- 依次根据peerEpoch,zxid,,sid来
- peerEpoch代表所处周期,越大则投票越新
- peerEpoch相同时,zxid代表一个周期中的事务记录,越大则投票越新
- peerEpoch,zxid均相同时,sid大的赢(两个投票一样新,只是为了决定leader需要有大小关系)
选举投票leader的验证问题
- 如果消息发送方state是looking,则termPredicate看是否过半即可
- 如果消息发送方state是following或者leading,则ooePredicate看是否过半,且leader机器发出ack知道了自己是leader即可
集群中是否所有机器是否都是网络互通
这里集群不是所有列表,而是所有leading和following的机器,不是网络互通的,比如1
2
3
4
5三台机器ABC,AB网络不通
但是A,B,C投票都给C
C收到三张票,过半,自己成为leader
B知道C得到了两张票,分别是BC投给C(B不知道A投给了C),也过半,自己成为follower
同理,A也成为follower
是否会出现looking机器和leader机器网络不通,但收了过半的leader投票,因此认定了leader的合理性
情景:1
2
31.假设5台机器ABCDE,ABCD已经形成集群,以D为leader
2.这时E以looking状态进来,收到了ABC以following状态的投票,这时就过半了
3.E会不会把D当成leader
这就是checkLeader函数的意义,里面会有检查1
2
3if(leader != self.getId()){// 自己不为leader
if(votes.get(leader) == null) predicate = false;// 投票记录中,没有来自leader的投票
else if(votes.get(leader).getState() != ServerState.LEADING) predicate = false;//leader不知道自己是leader
如果网络不通,那么就会votes.get(leader) == null,因此E不会把D当成leader
加入一个已经有的集群,走的什么流程
在上面checkLeader意义处也带过了,就是收了一堆following和leader机器的回复,然后进行过半验证以及leader验证即可
竞选leader是”广播”吗?
选举leader不是广播,后续一致性同步才是广播。这里就是所有server互相通信完成的
leader选举在server中启动步骤的位置
