分库分表sharding-jdbc源码解析
[TOC]
sharding-jdbc架构
架构图
核心概念
LogicTable
数据分片的逻辑表,对于水平拆分的数据库(表),同一类表的总称。例:订单数据根据主键尾数拆分为10张表,分别是t_order_0到t_order_9,他们的逻辑表名为t_order。
ActualTable
在分片的数据库中真实存在的物理表。即上个示例中的t_order_0到t_order_9。
DataNode
数据分片的最小单元。由数据源名称和数据表组成,例:ds_1.t_order_0。配置时默认各个分片数据库的表结构均相同,直接配置逻辑表和真实表对应关系即可。如果各数据库的表结果不同,可使用ds.actual_table配置。
BindingTable
指在任何场景下分片规则均一致的主表和子表。例:订单表和订单项表,均按照订单ID分片,则此两张表互为BindingTable关系。BindingTable关系的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。举例说明,如果SQL为:1
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在不配置绑定表关系时,假设分片键order_id将数值10路由至第0片,将数值11路由至第1片,那么路由后的SQL应该为4条,它们呈现为笛卡尔积:
1 | SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11); |
在配置绑定表关系后,路由的SQL应该为2条:
1 | SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11); |
其中t_order在FROM的最左侧,Sharding-Sphere将会以它作为整个绑定表的主表。所有路由计算将会只使用主表的策略,那么t_order_item表的分片计算将会使用t_order的条件。故绑定表之间的分区键要完全相同。
ShardingColumn
分片字段。用于将数据库(表)水平拆分的关键字段。例:订单表订单ID分片尾数取模分片,则订单ID为分片字段。SQL中如果无分片字段,将执行全路由,性能较差。Sharding-JDBC支持多分片字段。
ShardingAlgorithm
分片算法。Sharding-JDBC通过分片算法将数据分片,支持通过等号、BETWEEN和IN分片。分片算法目前需要业务方开发者自行实现,可实现的灵活度非常高。未来Sharding-JDBC也将会实现常用分片算法,如range,hash和tag等。
SQL Hint
对于分片字段非SQL决定,而由其他外置条件决定的场景,可使用SQL Hint灵活的注入分片字段。例:内部系统,按照员工登录ID分库,而数据库中并无此字段。SQL Hint支持通过ThreadLocal和SQL注释(待实现)两种方式使用。
Config Map
通过ConfigMap可以配置分库分表或读写分离数据源的元数据,可通过调用ConfigMapContext.getInstance()获取ConfigMap中的shardingConfig和masterSlaveConfig数据。例:如果机器权重不同则流量可能不同,可通过ConfigMap配置机器权重元数据。
LogicIndex
数据分片的逻辑索引名称,DDL语句中水平拆分的表,同一类表的总称。例:订单数据根据主键尾数拆分为10张表,分别是t_order_0到t_order_9,他们的逻辑表名为t_order,对于DROP INDEX t_order_index语句, 需在TableRule中配置逻辑索引t_order_index。
配置
配置sharding-jdbc1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30(name = "shardingDataSource")
DataSource getShardingDataSource() throws SQLException {
Map<String, DataSource> dataSourceMap = new HashMap<>();
/**
* 将dataSource纳入shardingDataSource管理
*/
dataSourceMap.put("souche_bilocation", dataSource);
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
/**
* 定义分表算法
*/
TableRuleConfiguration tableRuleConfig = new TableRuleConfiguration();
/**
* 设置逻辑表(逻辑表就是我们写在SQL中的表名)
*/
tableRuleConfig.setLogicTable("customer_track");
/**
* 设置实际表(最后我们数据落地的表,这里就是cutomer_track_0,customer_track_1)
*/
tableRuleConfig.setActualDataNodes("souche_bilocation.customer_track_${0..1}");
/**
* 设置分表配置,这里分表字段是user_id,算法就是实现的hashcode取余算法
*/
tableRuleConfig.setTableShardingStrategyConfig(
new StandardShardingStrategyConfiguration("user_id", StringModeShardingAlgorithm.class.getName()));
shardingRuleConfig.getTableRuleConfigs().add(tableRuleConfig);
return ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig,new ConcurrentHashMap<String, Object>(), new Properties());
}
执行
前提
本文内容基于以下前提:
shardingjdbc版本为2.0.3;
1
2
3
4
5<dependency>
<groupId>io.shardingjdbc</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>2.0.3</version>
</dependency>流程以
preparedStatement.executeQuery()方式执行;Statement.executeQuery()依赖的是StatementRoutingEngine;preparedStatement.executeQuery()依赖的是PreparedStatementRoutingEngine;
StatementRoutingEngine和PreparedStatementRoutingEngine内部都是依赖ParsingSQLRouter进行解析和路由的,所以整体的执行过程是一致的。
sql解析
添加字段
appendDerivedColumns()和appendDerivedOrderBy()方法分别处理avg函数字段和排序字段的添加。1
2
3
4
5
6
7
8
9
10
11
12
13
14public abstract class AbstractSelectParser implements SQLParser {
public final SelectStatement parse() {
SelectStatement result = parseInternal();
if (result.containsSubQuery()) {
result = result.mergeSubQueryStatement();
}
// TODO move to rewrite
appendDerivedColumns(result);
appendDerivedOrderBy(result);
return result;
}
}
avg函数添加字段及group字段补充(appendDerivedColumns)
sql中有avg()函数时,想要正确的从几个库表中获取数据,几个avg()求和作平均得到的结果是不对的,必须采用sum(field)/count(field),所以要将原来的select avg(field) from改写为select sum(field), count(field)
这个阶段发生在MySQLSelectParser.parse()(实际是AbstractSelectParser.parse())。
1 | private void appendDerivedColumns(final SelectStatement selectStatement) { |
有group无order添加排序(appendDerivedOrderBy)
如果有group by但是没有order by,那就加上group by的字段为排序字段。1
2
3
4
5
6private void appendDerivedOrderBy(final SelectStatement selectStatement) {
if (!selectStatement.getGroupByItems().isEmpty() && selectStatement.getOrderByItems().isEmpty()) {
selectStatement.getOrderByItems().addAll(selectStatement.getGroupByItems());
selectStatement.getSqlTokens().add(new OrderByToken(selectStatement.getGroupByLastPosition()));
}
}
路由
这里的路由是指根据逻辑表名找到实际数据库和物理表名的过程。
路由发生在 ParsingSQLRouter.route() -> RoutingEngine.route()。
ParsingSQLRouter.route()中根据sql是DDL/无表/单表/多表,使用不同的RoutingEngine。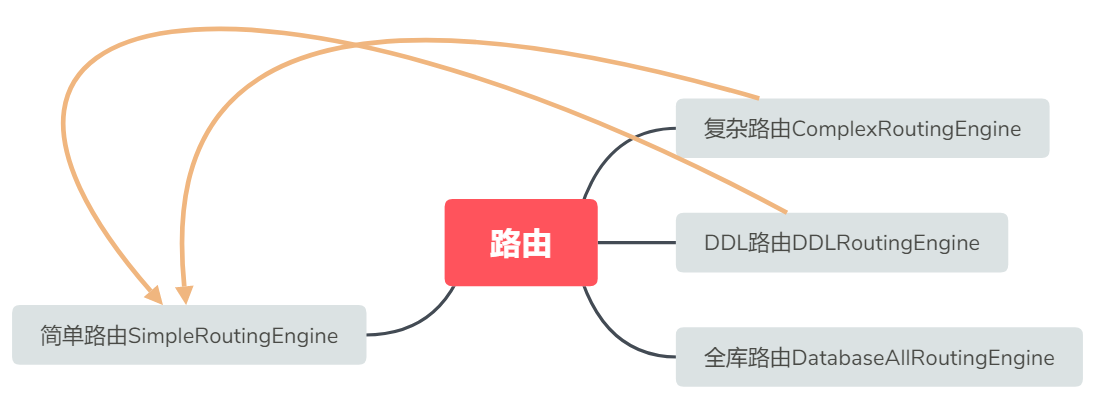
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15private RoutingResult route(final List<Object> parameters, final SQLStatement sqlStatement) {
Collection<String> tableNames = sqlStatement.getTables().getTableNames();
RoutingEngine routingEngine;
if (sqlStatement instanceof DDLStatement) {
routingEngine = new DDLRoutingEngine(shardingRule, parameters, (DDLStatement) sqlStatement);
} else if (tableNames.isEmpty()) {
routingEngine = new DatabaseAllRoutingEngine(shardingRule.getDataSourceMap());
} else if (1 == tableNames.size() || shardingRule.isAllBindingTables(tableNames) || shardingRule.isAllInDefaultDataSource(tableNames)) {
routingEngine = new SimpleRoutingEngine(shardingRule, parameters, tableNames.iterator().next(), sqlStatement);
} else {
// TODO config for cartesian set
routingEngine = new ComplexRoutingEngine(shardingRule, parameters, tableNames, sqlStatement);
}
return routingEngine.route();
}
路由结果(RoutingResult)会在ParsingSQLRouter.route()中用于获取TableUnit。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
public SQLRouteResult route(final String logicSQL, final List<Object> parameters, final SQLStatement sqlStatement) {
// ...省略无关代码
// route()执行了上文的路由过程,获得CartesianRoutingResult
RoutingResult routingResult = route(parameters, sqlStatement);
/**
* 这里CartesianRoutingResult单独处理
**/
if (routingResult instanceof CartesianRoutingResult) {
for (CartesianDataSource cartesianDataSource : ((CartesianRoutingResult) routingResult).getRoutingDataSources()) {
// cartesianTableReference中包含了一个db中的所有实际表名
for (CartesianTableReference cartesianTableReference : cartesianDataSource.getRoutingTableReferences()) {
result.getExecutionUnits().add(new SQLExecutionUnit(cartesianDataSource.getDataSource(), rewriteEngine.generateSQL(cartesianTableReference, sqlBuilder)));
}
}
} else { // 通用处理
for (TableUnit each : routingResult.getTableUnits().getTableUnits()) {
result.getExecutionUnits().add(new SQLExecutionUnit(each.getDataSourceName(), rewriteEngine.generateSQL(each, sqlBuilder)));
}
}
if (showSQL) {
SQLLogger.logSQL(logicSQL, sqlStatement, result.getExecutionUnits(), parameters);
}
return result;
}
单表路由(SimpleRoutingEngine)
SimpleRoutingEngine是所有路由的核心,使用配置的TableRule进行路由。
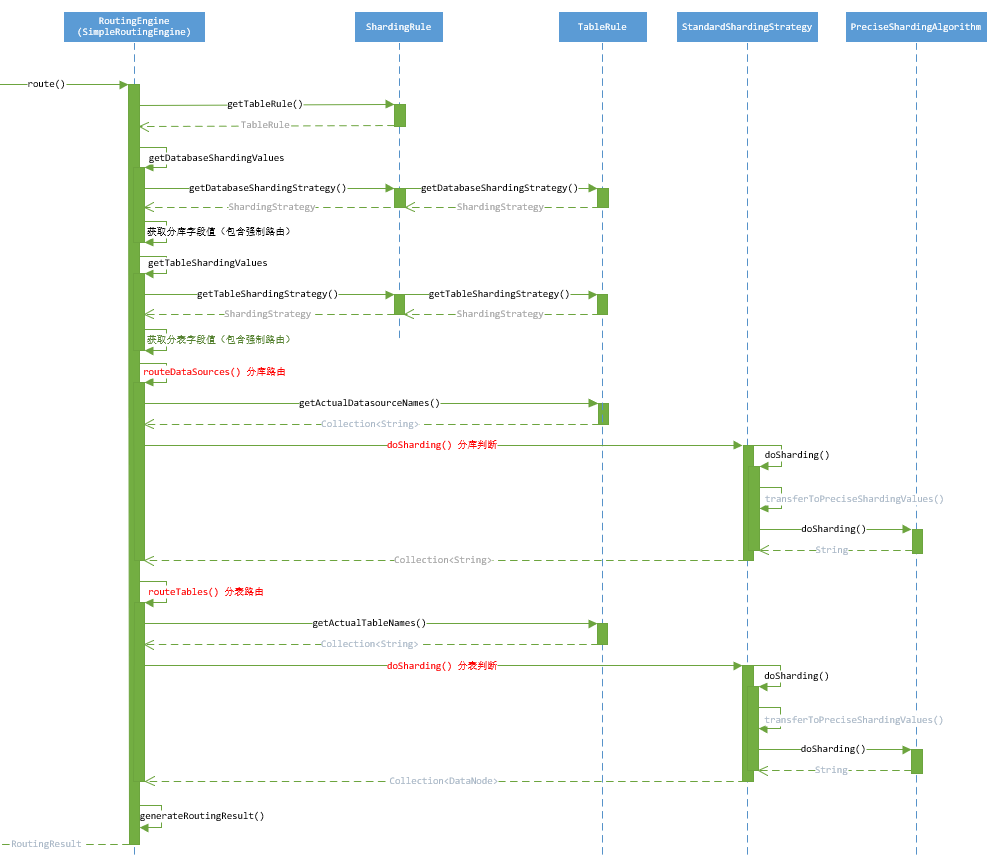
路由解析:
- 获取db和table路由字段值,如果是强制路由则从HintManagerHolder获取;
- 根据StandardShardingStrategyConfiguration配置的ShardingStrategy进行db路由;
- 根据StandardShardingStrategyConfiguration配置的ShardingStrategy进行table路由;
- 路由结果封装。
1 |
|
DDL路由(DDLRoutingEngine)
DDL路由实际使用的是SimpleRoutingEngine,和单表路由一致,详见单表路由。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public final class DDLRoutingEngine implements RoutingEngine {
private final ShardingRule shardingRule;
private final List<Object> parameters;
private final DDLStatement ddlStatement;
public RoutingResult route() {
// 使用SimpleRoutingEngine
return new SimpleRoutingEngine(shardingRule, parameters, getLogicTableName(), ddlStatement).route();
}
private String getLogicTableName() {
if (ddlStatement.getTables().isEmpty()) {
return shardingRule.getLogicTableName(getIndexToken().getIndexName());
}
return ddlStatement.getTables().getSingleTableName();
}
private IndexToken getIndexToken() {
Preconditions.checkState(1 == ddlStatement.getSqlTokens().size());
return (IndexToken) ddlStatement.getSqlTokens().get(0);
}
}
无表路由(DatabaseAllRoutingEngine)
无表路由返回值封装了空表new TableUnit(each, "", ""),其中each代表各个db的datasource。1
2
3
4
5
6
7
8
9
10
11
12
13
14
public final class DatabaseAllRoutingEngine implements RoutingEngine {
private final Map<String, DataSource> dataSourceMap;
public RoutingResult route() {
RoutingResult result = new RoutingResult();
for (String each : dataSourceMap.keySet()) {
result.getTableUnits().getTableUnits().add(new TableUnit(each, "", ""));
}
return result;
}
}
多表路由(ComplexRoutingEngine)
绑定表
配置绑定表
ShardingDataSource配置shardingRuleConfig.setBindingTableGroups()即可绑定表。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25(name = "shardingDataSource")
DataSource getShardingDataSource() throws SQLException {
Map<String, DataSource> dataSourceMap = new HashMap<>();
dataSourceMap.put("souche_bilocation_0", dataSource);
dataSourceMap.put("souche_bilocation_1", dataSource);
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.setDefaultDatabaseShardingStrategyConfig(new StandardShardingStrategyConfiguration("id", StringModeShardingAlgorithm.class.getName()));
TableRuleConfiguration tableRuleConfig = new TableRuleConfiguration();
tableRuleConfig.setLogicTable("customer_track");
tableRuleConfig.setActualDataNodes("souche_bilocation_${0..1}.customer_track_${0..1}");
tableRuleConfig.setTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("id", StringModeShardingAlgorithm.class.getName()));
shardingRuleConfig.getTableRuleConfigs().add(tableRuleConfig);
TableRuleConfiguration customer_track_detail = new TableRuleConfiguration();
customer_track_detail.setLogicTable("customer_track_detail");
customer_track_detail.setActualDataNodes("souche_bilocation_${0..1}.customer_track_detail_${0..1}");
customer_track_detail.setTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("track_id", StringModeShardingAlgorithm.class.getName()));
shardingRuleConfig.getTableRuleConfigs().add(customer_track_detail);
// 绑定表
shardingRuleConfig.setBindingTableGroups(Arrays.asList("customer_track,customer_track_detail"));
return ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig,new ConcurrentHashMap<String, Object>(), new Properties());
}
在ShardingRule构造器中会将bindingTableGroups转换成BindingTableRules。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public ShardingRule(final Map<String, DataSource> dataSourceMap, final String defaultDataSourceName, final Collection<TableRule> tableRules,
final Collection<String> bindingTableGroups, final ShardingStrategy defaultDatabaseShardingStrategy,
final ShardingStrategy defaultTableShardingStrategy, final KeyGenerator defaultKeyGenerator) {
// ... 省略其他
for (String group : bindingTableGroups) {
List<TableRule> tableRulesForBinding = new LinkedList<>();
// 以,分割
for (String logicTableNameForBindingTable : StringUtil.splitWithComma(group)) {
tableRulesForBinding.add(getTableRule(logicTableNameForBindingTable));
}
// 绑定表的rule存在BindingTableRule中
this.bindingTableRules.add(new BindingTableRule(tableRulesForBinding));
}
// ... 省略其他
}
BindingTableRule
BindingTableRule中保存了绑定表的TableRule集合。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
public final class BindingTableRule {
private final List<TableRule> tableRules;
/**
* Adjust contains this logic table in this rule.
*
* @param logicTableName logic table name
* @return contains this logic table or not
*/
public boolean hasLogicTable(final String logicTableName) {
for (TableRule each : tableRules) {
if (each.getLogicTable().equals(logicTableName.toLowerCase())) {
return true;
}
}
return false;
}
/**
* Deduce actual table name from other actual table name in same binding table rule.
* 从同一绑定表规则中的其他实际表名中推导出该逻辑表的实际表名。
* @param dataSource data source name
* @param logicTable logic table name
* @param otherActualTable other actual table name in same binding table rule
* @return actual table name
*/
public String getBindingActualTable(final String dataSource, final String logicTable, final String otherActualTable) {
int index = -1;
// 找出其它实际表(子表或者父表)所在的位置(index)
for (TableRule each : tableRules) {
index = each.findActualTableIndex(dataSource, otherActualTable);
if (-1 != index) {
break;
}
}
Preconditions.checkState(-1 != index, String.format("Actual table [%s].[%s] is not in table config", dataSource, otherActualTable));
// 根据其他实际表所在的位置(index)获取当前位置的logicTable对应的实际表
for (TableRule each : tableRules) {
if (each.getLogicTable().equals(logicTable.toLowerCase())) {
return each.getActualDataNodes().get(index).getTableName().toLowerCase();
}
}
throw new IllegalStateException(String.format("Cannot find binding actual table, data source: %s, logic table: %s, other actual table: %s", dataSource, logicTable, otherActualTable));
}
// 所有逻辑表
Collection<String> getAllLogicTables() {
return Lists.transform(tableRules, new Function<TableRule, String>() {
public String apply(final TableRule input) {
return input.getLogicTable().toLowerCase();
}
});
}
}
路由解析
路由逻辑:
- shardingRule获取TableRule,如果当前表有绑定表且已经保存,则忽略当前表;
- 若没有绑定表或有绑定表但绑定的表未保存,则使用SimpleRoutingEngine路由,保存路由结果;
- 获取当前表的绑定表并保存;
- 如果只有一个SimpleRoutingEngine路由结果,就返回路由结果;
- 多个路由结果,就使用CartesianRoutingEngine)再路由。
1 |
|
笛卡尔路由引擎(CartesianRoutingEngine)
笛卡尔路由引擎的前提是有多个SimpleRoutingEngine路由结果。
路由逻辑:
将所有的路由结果使用CartesianRoutingResult)按DataSource分类保存。
直接看CartesianRoutingEngine的route方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90public final class CartesianRoutingEngine implements RoutingEngine {
// 路由结果,构造器阶段传入
private final Collection<RoutingResult> routingResults;
public CartesianRoutingResult route() {
CartesianRoutingResult result = new CartesianRoutingResult();
// key是datasource名称,value是逻辑表名列表
for (Entry<String, Set<String>> entry : getDataSourceLogicTablesMap().entrySet()) {
// 根据逻辑表获取实际表名
List<Set<String>> actualTableGroups = getActualTableGroups(entry.getKey(), entry.getValue());
// 封装成TableUnit
List<Set<TableUnit>> tableUnitGroups = toTableUnitGroups(entry.getKey(), actualTableGroups);
// getCartesianTableReferences将TableUnit转成CartesianTableReference
// 合并详见CartesianRoutingResult
result.merge(entry.getKey(), getCartesianTableReferences(Sets.cartesianProduct(tableUnitGroups)));
}
log.trace("cartesian tables sharding result: {}", result);
return result;
}
// key是datasource名称,value是逻辑表名列表
private Map<String, Set<String>> getDataSourceLogicTablesMap() {
// 获取DataSource的交集
Collection<String> intersectionDataSources = getIntersectionDataSources();
// key是datasource名称,value是逻辑表名列表
Map<String, Set<String>> result = new HashMap<>(routingResults.size());
for (RoutingResult each : routingResults) {
for (Entry<String, Set<String>> entry : each.getTableUnits().getDataSourceLogicTablesMap(intersectionDataSources).entrySet()) {
if (result.containsKey(entry.getKey())) {
result.get(entry.getKey()).addAll(entry.getValue());
} else {
result.put(entry.getKey(), entry.getValue());
}
}
}
return result;
}
// 取routingResults的DataSource交集
private Collection<String> getIntersectionDataSources() {
Collection<String> result = new HashSet<>();
for (RoutingResult each : routingResults) {
if (result.isEmpty()) {
result.addAll(each.getTableUnits().getDataSourceNames());
}
// retainAll 取交集
result.retainAll(each.getTableUnits().getDataSourceNames());
}
return result;
}
private List<Set<String>> getActualTableGroups(final String dataSource, final Set<String> logicTables) {
List<Set<String>> result = new ArrayList<>(logicTables.size());
for (RoutingResult each : routingResults) {
result.addAll(each.getTableUnits().getActualTableNameGroups(dataSource, logicTables));
}
return result;
}
private List<Set<TableUnit>> toTableUnitGroups(final String dataSource, final List<Set<String>> actualTableGroups) {
List<Set<TableUnit>> result = new ArrayList<>(actualTableGroups.size());
for (Set<String> each : actualTableGroups) {
result.add(new HashSet<>(Lists.transform(new ArrayList<>(each), new Function<String, TableUnit>() {
public TableUnit apply(final String input) {
return findTableUnit(dataSource, input);
}
})));
}
return result;
}
private TableUnit findTableUnit(final String dataSource, final String actualTable) {
for (RoutingResult each : routingResults) {
Optional<TableUnit> result = each.getTableUnits().findTableUnit(dataSource, actualTable);
if (result.isPresent()) {
return result.get();
}
}
throw new IllegalStateException(String.format("Cannot found routing table factor, data source: %s, actual table: %s", dataSource, actualTable));
}
private List<CartesianTableReference> getCartesianTableReferences(final Set<List<TableUnit>> cartesianTableUnitGroups) {
List<CartesianTableReference> result = new ArrayList<>(cartesianTableUnitGroups.size());
for (List<TableUnit> each : cartesianTableUnitGroups) {
result.add(new CartesianTableReference(each));
}
return result;
}
}
卡迪尔路由结果(CartesianRoutingResult)
merge逻辑:
- 将routingTableReferences按照dataSource分类保存。
1 |
|
CartesianRoutingResult继承了RoutingResult类,但并没有给RoutingResult的属性TableUnits tableUnits赋值,所以在实际使用CartesianRoutingResult类获取路由结果时,必然不能使用统一代码处理。
CartesianRoutingResult在ParsingSQLRouter.route()中单独处理。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
public SQLRouteResult route(final String logicSQL, final List<Object> parameters, final SQLStatement sqlStatement) {
// ...省略无关代码
// route()执行了上文的路由过程,获得CartesianRoutingResult
RoutingResult routingResult = route(parameters, sqlStatement);
/**
* 这里CartesianRoutingResult单独处理
**/
if (routingResult instanceof CartesianRoutingResult) {
for (CartesianDataSource cartesianDataSource : ((CartesianRoutingResult) routingResult).getRoutingDataSources()) {
// cartesianTableReference中包含了一个db中的所有实际表名
for (CartesianTableReference cartesianTableReference : cartesianDataSource.getRoutingTableReferences()) {
result.getExecutionUnits().add(new SQLExecutionUnit(cartesianDataSource.getDataSource(), rewriteEngine.generateSQL(cartesianTableReference, sqlBuilder)));
}
}
} else { // 通用处理
for (TableUnit each : routingResult.getTableUnits().getTableUnits()) {
result.getExecutionUnits().add(new SQLExecutionUnit(each.getDataSourceName(), rewriteEngine.generateSQL(each, sqlBuilder)));
}
}
if (showSQL) {
SQLLogger.logSQL(logicSQL, sqlStatement, result.getExecutionUnits(), parameters);
}
return result;
}
sql改写(SQLRewriteEngine)
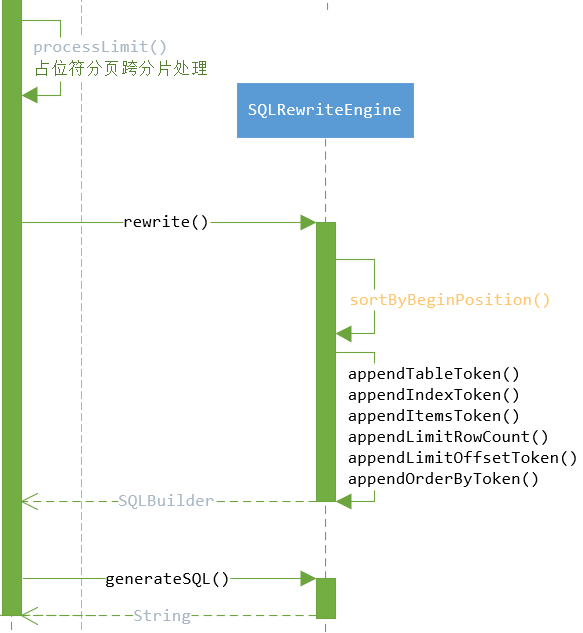
sql改写发生在.ParsingSQLRouter.route()->rewriteEngine.rewrite()。
sql改写在SQLRewriteEngine类中,有两个核心方法:
- rewrite方法:负责将sql语句改写,并分割成块,结构例如:
select * from, tableToken, where id=? - generateSQL方法:负责生成改写后的sql语句,这里主要对表名进行替换。
SQLRewriteEngine改写了表名、limit的偏移量和行数。
SQLBuilder
先认识一下rewrite方法执行后保存sql段的类SQLBuilder。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54public final class SQLBuilder {
// 保存sql段
private final List<Object> segments;
// 用于保存不改变的sql
private StringBuilder currentSegment;
public SQLBuilder() {
segments = new LinkedList<>();
currentSegment = new StringBuilder();
segments.add(currentSegment);
}
// 保存不变的sql
public void appendLiterals(final String literals) {
currentSegment.append(literals);
}
// 保存table段
public void appendTable(final String tableName) {
segments.add(new TableToken(tableName));
currentSegment = new StringBuilder();
segments.add(currentSegment);
}
// 保存index段
public void appendIndex(final String indexName, final String tableName) {
segments.add(new IndexToken(indexName, tableName));
currentSegment = new StringBuilder();
segments.add(currentSegment);
}
// 生成改写后的sql语句
// tableTokens: <逻辑表名>:<实际表名>
// customer_track:customer_track_1
public String toSQL(final Map<String, String> tableTokens) {
// 保存最终的sql语句
StringBuilder result = new StringBuilder();
for (Object each : segments) {
// 替换表名
if (each instanceof TableToken && tableTokens.containsKey(((TableToken) each).tableName)) {
result.append(tableTokens.get(((TableToken) each).tableName));
} else if (each instanceof IndexToken) {
// 索引替换表名
IndexToken indexToken = (IndexToken) each;
result.append(indexToken.indexName);
String tableName = tableTokens.get(indexToken.tableName);
if (!Strings.isNullOrEmpty(tableName)) {
result.append("_");
result.append(tableName);
}
} else {
result.append(each);
}
}
return result.toString();
}
// ... 省略其它
}
SQLRewriteEngine.rewrite()
isRewriteLimit 由是否查询多个库表决定。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30public SQLBuilder rewrite(final boolean isRewriteLimit) {
SQLBuilder result = new SQLBuilder();
if (sqlTokens.isEmpty()) {
result.appendLiterals(originalSQL);
return result;
}
int count = 0;
sortByBeginPosition();
for (SQLToken each : sqlTokens) {
if (0 == count) {
// sql语句最前面一段不用修改的内容保存
result.appendLiterals(originalSQL.substring(0, each.getBeginPosition()));
}
if (each instanceof TableToken) {
appendTableToken(result, (TableToken) each, count, sqlTokens);
} else if (each instanceof IndexToken) {
appendIndexToken(result, (IndexToken) each, count, sqlTokens);
} else if (each instanceof ItemsToken) {
appendItemsToken(result, (ItemsToken) each, count, sqlTokens);
} else if (each instanceof RowCountToken) {
appendLimitRowCount(result, (RowCountToken) each, count, sqlTokens, isRewriteLimit);
} else if (each instanceof OffsetToken) {
appendLimitOffsetToken(result, (OffsetToken) each, count, sqlTokens, isRewriteLimit);
} else if (each instanceof OrderByToken) {
appendOrderByToken(result, count, sqlTokens);
}
count++;
}
return result;
}
SQLRewriteEngine.generateSQL()
1 | public String generateSQL(final TableUnit tableUnit, final SQLBuilder sqlBuilder) { |
表名改写(TableToken)
sql的表名替换在生成sql语句时替换SQLRewriteEngine.generateSQL(),改写规则:将逻辑表替换成实际的物理表。
详见上面:
SQLRewriteEngine.generateSQL() -> SQLBuilder.toSQL()
索引改写(IndexToken)
索引改写就是将逻辑表索引改为实际物理表索引index_tableName,所以逻辑与表名改写一致。
分页改写
1 |
|
分页如果在limit中有占位符就会在ParsingSQLRouter.route() -> ParsingSQLRouter.processLimit()中作前置处理。
Limit带占位符前置处理
processLimit()如下:1
2
3
4
5
6
7
8
9
10
11private void processLimit(final List<Object> parameters, final SelectStatement selectStatement, final boolean isSingleRouting) {
// 只查一个库表时
if (isSingleRouting) {
selectStatement.setLimit(null);
return;
}
// 是否查所有,有group by/聚合函数且分组字段与排序字段不一致
boolean isNeedFetchAll = (!selectStatement.getGroupByItems().isEmpty() || !selectStatement.getAggregationSelectItems().isEmpty()) && !selectStatement.isSameGroupByAndOrderByItems();
// 改写
selectStatement.getLimit().processParameters(parameters, isNeedFetchAll);
}
改写在Limit类中,parameters占位符对应的参数,改写逻辑如下:
- 行数根据isFetchAll,true设置行数为最大Integer;不然要是数据库是MySQL/H2/PostgreSQL则设置成Offset + rowCount;其他就是参数传多少就是多少;
- 偏移量直接设置成0;
1 | public void processParameters(final List<Object> parameters, final boolean isFetchAll) { |
行数改写(RowCountToken)
改写limit的行数在SQLRewriteEngine.rewrite(),改写规则如下:
- 只查一个库表的不改写;
- 有group by或聚合函数且分组字段与排序字段不相同,则设置行数为Integer.MAX_VALUE,即数据库分页;
- 有group by或聚合函数且分组字段与排序字段相同,行数 = offset+行数
1 | private void appendLimitRowCount(final SQLBuilder sqlBuilder, final RowCountToken rowCountToken, |
偏移量(Offset)改写(OffsetToken)
改写limit的偏移量(Offset)在SQLRewriteEngine.rewrite(),改写规则如下:
- 需要查询多个库表就直接把offset设为0
1 | private void appendLimitOffsetToken(final SQLBuilder sqlBuilder, final OffsetToken offsetToken, |
排序(OrderByToken)
在SQLRewriteEngine.rewrite()中没有对排序进行改写,appendOrderByToken()根据解析的SelectStatement生成order by的语句。
1 | private void appendOrderByToken(final SQLBuilder sqlBuilder, final int count, final List<SQLToken> sqlTokens) { |
结果归并
结果归并在ShardingPreparedStatement.executeQuery()->MergeEngine.merge()中执行:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public ResultSet executeQuery() throws SQLException {
ResultSet result;
try {
// 路由完成
Collection<PreparedStatementUnit> preparedStatementUnits = route();
// 执行sql
List<ResultSet> resultSets = new PreparedStatementExecutor(
getConnection().getShardingContext().getExecutorEngine(), routeResult.getSqlStatement().getType(), preparedStatementUnits, getParameters()).executeQuery();
// 结果归并
result = new ShardingResultSet(resultSets, new MergeEngine(resultSets, (SelectStatement) routeResult.getSqlStatement()).merge(), this);
} finally {
clearBatch();
}
currentResultSet = result;
return result;
}
无归并(IteratorStreamResultSetMerger)
没有排序、group、聚合函数的查询会封装成IteratorStreamResultSetMerger。
IteratorStreamResultSetMerger中依次迭代结果集。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30public final class IteratorStreamResultSetMerger extends AbstractStreamResultSetMerger {
private final Iterator<ResultSet> resultSets;
public IteratorStreamResultSetMerger(final List<ResultSet> resultSets) {
this.resultSets = resultSets.iterator();
setCurrentResultSet(this.resultSets.next());
}
public boolean next() throws SQLException {
if (getCurrentResultSet().next()) {
return true;
}
if (!resultSets.hasNext()) {
return false;
}
// 迭代结果集
setCurrentResultSet(resultSets.next());
boolean hasNext = getCurrentResultSet().next();
if (hasNext) {
return true;
}
while (!hasNext && resultSets.hasNext()) {
setCurrentResultSet(resultSets.next());
hasNext = getCurrentResultSet().next();
}
return hasNext;
}
}
排序归并(OrderByStreamResultSetMerger)
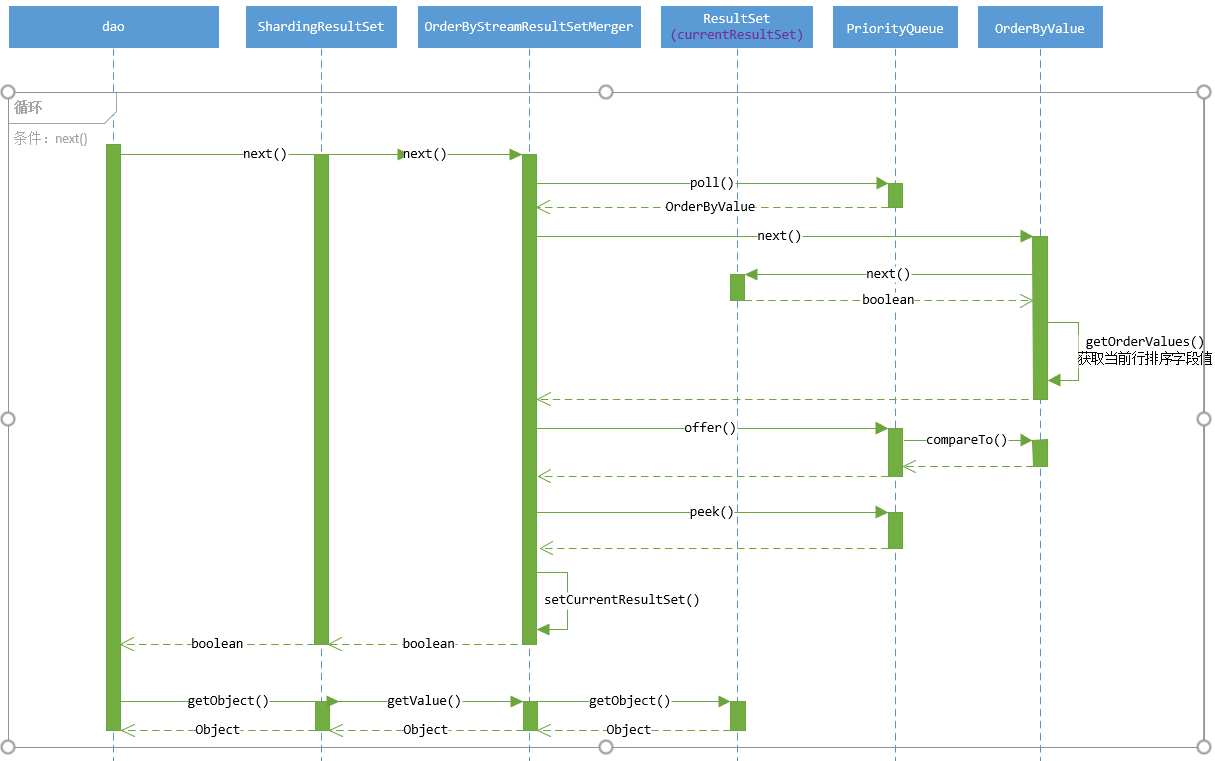
排序逻辑
- 利用优先级队列,比较各结果集当前行排序字段值,按比较结果排列结果集;
- 取队列头的结果集的一行数据;
- 运行next()方法,将队列头的结果集取出队列,执行该结果集的next()方法使光标指向下一行,再将该结果集存入队列排序;
属性1
2
3
4
5
6
7
8
9public class OrderByStreamResultSetMerger extends AbstractStreamResultSetMerger {
// 排序字段信息
private final List<OrderItem> orderByItems;
// 结果集队列
private final Queue<OrderByValue> orderByValuesQueue;
private boolean isFirstNext;
}
构造器
构造器中将结果集以OrderByValue类的形式存入优先级队列中。
1 | public OrderByStreamResultSetMerger(final List<ResultSet> resultSets, final List<OrderItem> orderByItems) throws SQLException { |
next()方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public boolean next() throws SQLException {
if (orderByValuesQueue.isEmpty()) {
return false;
}
if (isFirstNext) {
isFirstNext = false;
return true;
}
// 取出队列头部元素
OrderByValue firstOrderByValue = orderByValuesQueue.poll();
// 光标移动
if (firstOrderByValue.next()) {
// 存入队列,重排序
orderByValuesQueue.offer(firstOrderByValue);
}
if (orderByValuesQueue.isEmpty()) {
return false;
}
// 设置当前结果集
setCurrentResultSet(orderByValuesQueue.peek().getResultSet());
return true;
}
OrderByValue类
- OrderByStreamResultSetMerger的优先级队列通过OrderByValue实现的Comparable接口来判断优先级;
- OrderByValue的比较的逻辑是依次比较排序字段的值的大小,第一个不相等的排序字段大小代表了OrderByValue的大小(两个结果集中的光标指向行数据依次比较排序字段);
- OrderByValue的next()方法会在OrderByStreamResultSetMerger的next()方法中被调用;
- OrderByValue的next()会推动结果集(resultSet.next())指向下一行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40public final class OrderByValue implements Comparable<OrderByValue> {
private final ResultSet resultSet;
// 排序字段信息
private final List<OrderItem> orderByItems;
// 一行数据中包含排序字段的字段值
private List<Comparable<?>> orderValues;
// next方法中会getOrderValues()获取当前行的排序字段值
public boolean next() throws SQLException {
// 调用结果集的next()方法
boolean result = resultSet.next();
orderValues = result ? getOrderValues() :
Collections.<Comparable<?>>emptyList();
return result;
}
// 遍历orderByItems排序字段,获取对应的字段值
private List<Comparable<?>> getOrderValues() throws SQLException {
List<Comparable<?>> result = new ArrayList<>(orderByItems.size());
for (OrderItem each : orderByItems) {
Object value = resultSet.getObject(each.getIndex());
Preconditions.checkState(null == value || value instanceof Comparable, "Order by value must implements Comparable");
result.add((Comparable<?>) value);
}
return result;
}
// 挨个比较排序字段的值,有一个不相等就返回
public int compareTo(final OrderByValue o) {
for (int i = 0; i < orderByItems.size(); i++) {
OrderItem thisOrderBy = orderByItems.get(i);
int result = ResultSetUtil.compareTo(orderValues.get(i), o.orderValues.get(i), thisOrderBy.getType(), thisOrderBy.getNullOrderType());
if (0 != result) {
return result;
}
}
return 0;
}
}
聚合函数结果归并
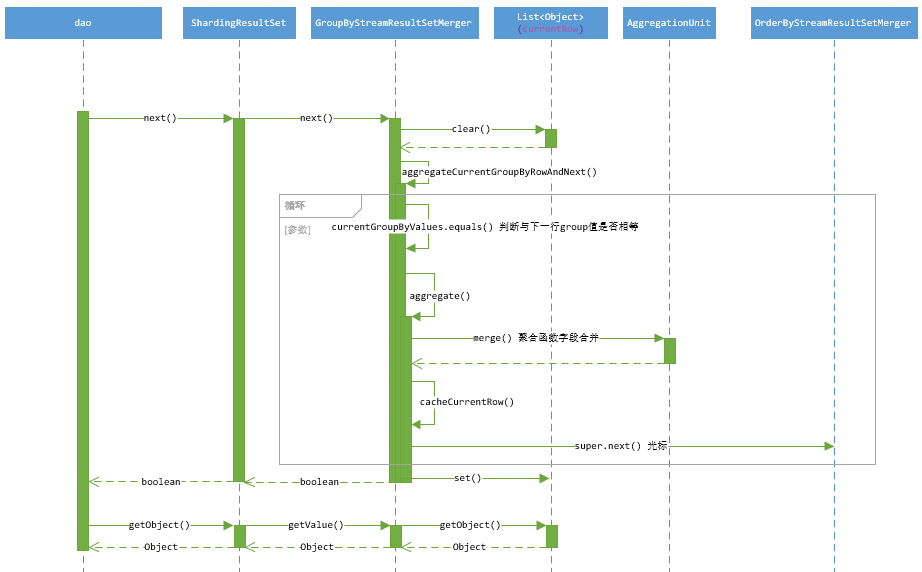
GroupByStreamResultSetMerger(group by 字段与排序字段相同)
属性1
2
3
4
5
6
7
8
9
10public final class GroupByStreamResultSetMerger extends OrderByStreamResultSetMerger {
// key字段名,value字段所在位置
private final Map<String, Integer> labelAndIndexMap;
// sql
private final SelectStatement selectStatement;
// 当前行数据(归并处理后的数据)
private final List<Object> currentRow;
// group by字段值,用于归并判断,在更新currentRow数据后指向下一行
private List<?> currentGroupByValues;
}
构造器1
2
3
4
5
6
7
8
9
10public GroupByStreamResultSetMerger(
final Map<String, Integer> labelAndIndexMap, final List<ResultSet> resultSets, final SelectStatement selectStatement) throws SQLException {
// OrderByStreamResultSetMerger 排序
super(resultSets, selectStatement.getOrderByItems());
this.labelAndIndexMap = labelAndIndexMap;
this.selectStatement = selectStatement;
currentRow = new ArrayList<>(labelAndIndexMap.size());
// 获得group by 字段值
currentGroupByValues = getOrderByValuesQueue().isEmpty() ? Collections.emptyList() : new GroupByValue(getCurrentResultSet(), selectStatement.getGroupByItems()).getGroupValues();
}
读取数据1
2
3
4
5
6
7
8
9
10
public Object getValue(final int columnIndex, final Class<?> type) throws SQLException {
return currentRow.get(columnIndex - 1);
}
public Object getValue(final String columnLabel, final Class<?> type) throws SQLException {
Preconditions.checkState(labelAndIndexMap.containsKey(columnLabel), String.format("Can't find columnLabel: %s", columnLabel));
return currentRow.get(labelAndIndexMap.get(columnLabel) - 1);
}
next()方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
public boolean next() throws SQLException {
currentRow.clear();
if (getOrderByValuesQueue().isEmpty()) {
return false;
}
if (isFirstNext()) {
super.next();
}
// 归并
if (aggregateCurrentGroupByRowAndNext()) {
// currentGroupByValues 指向下一行的group by 字段值
currentGroupByValues = new GroupByValue(getCurrentResultSet(), selectStatement.getGroupByItems()).getGroupValues();
}
return true;
}
// 归并
private boolean aggregateCurrentGroupByRowAndNext() throws SQLException {
boolean result = false;
// 聚集函数字段
Map<AggregationSelectItem, AggregationUnit> aggregationUnitMap = Maps.toMap(selectStatement.getAggregationSelectItems(), new Function<AggregationSelectItem, AggregationUnit>() {
public AggregationUnit apply(final AggregationSelectItem input) {
return AggregationUnitFactory.create(input.getType());
}
});
//currentGroupByValues当前的group字段值,与各行group字段比较,直到group字段值不一致
//第一次比较是自己比较自己
//super.next()推动结果集走向下一行,同时保持排序
while (currentGroupByValues.equals(new GroupByValue(getCurrentResultSet(), selectStatement.getGroupByItems()).getGroupValues())) {
// 聚集函数结果归并,例如count()函数就相加,avg就平均等
aggregate(aggregationUnitMap);
// 更新当前行的值,次数聚集函数的值不是归并后的值
cacheCurrentRow();
result = super.next();
if (!result) {
break;
}
}
// 此时将聚集函数归并后的值更新到相应的字段
setAggregationValueToCurrentRow(aggregationUnitMap);
return result;
}
private void aggregate(final Map<AggregationSelectItem, AggregationUnit> aggregationUnitMap) throws SQLException {
for (Entry<AggregationSelectItem, AggregationUnit> entry : aggregationUnitMap.entrySet()) {
List<Comparable<?>> values = new ArrayList<>(2);
if (entry.getKey().getDerivedAggregationSelectItems().isEmpty()) {
values.add(getAggregationValue(entry.getKey()));
} else {
for (AggregationSelectItem each : entry.getKey().getDerivedAggregationSelectItems()) {
values.add(getAggregationValue(each));
}
}
// 不同的聚集函数不同的merge
entry.getValue().merge(values);
}
}
GroupByMemoryResultSetMerger (group by字段与排序字段不一致)
归并逻辑
在构造器阶段将所有数据归并,遍历所有数据:
- 将group字段值相同的聚集函数字段进行归并;
- 将归并过的数据通过排序字段排序到List中,List中的元素代表一行数据;
- 获取List的迭代器memoryResultSetRows,通过迭代器next()。
属性1
2
3
4
5
6public final class GroupByMemoryResultSetMerger extends AbstractMemoryResultSetMerger {
private final SelectStatement selectStatement;
// MemoryResultSetRow 存储归并过的一行数据
private final Iterator<MemoryResultSetRow> memoryResultSetRows;
}
构造器1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62public GroupByMemoryResultSetMerger(
final Map<String, Integer> labelAndIndexMap, final List<ResultSet> resultSets, final SelectStatement selectStatement) throws SQLException {
super(labelAndIndexMap);
this.selectStatement = selectStatement;
// 初始化
memoryResultSetRows = init(resultSets);
}
private Iterator<MemoryResultSetRow> init(final List<ResultSet> resultSets) throws SQLException {
// value代表归并后数据
Map<GroupByValue, MemoryResultSetRow> dataMap = new HashMap<>(1024);
// key:group字段值,value:<聚合函数字段,聚合函数信息>
Map<GroupByValue, Map<AggregationSelectItem, AggregationUnit>> aggregationMap = new HashMap<>(1024);
// 遍历所有数据
for (ResultSet each : resultSets) {
while (each.next()) {
// group字段值
GroupByValue groupByValue = new GroupByValue(each, selectStatement.getGroupByItems());
// GroupByValue 为key是否已经存入dataMap和aggregationMap,没有就初始化存入
initForFirstGroupByValue(each, groupByValue, dataMap, aggregationMap);
// 聚集函数字段合并
aggregate(each, groupByValue, aggregationMap);
}
}
// 将归并过的数据aggregationMap更新到dataMap中
setAggregationValueToMemoryRow(dataMap, aggregationMap);
// 对归并数据按排序字段排序
List<MemoryResultSetRow> result = getMemoryResultSetRows(dataMap);
if (!result.isEmpty()) {
setCurrentResultSetRow(result.get(0));
}
return result.iterator();
}
private void initForFirstGroupByValue(final ResultSet resultSet, final GroupByValue groupByValue, final Map<GroupByValue, MemoryResultSetRow> dataMap,
final Map<GroupByValue, Map<AggregationSelectItem, AggregationUnit>> aggregationMap) throws SQLException {
if (!dataMap.containsKey(groupByValue)) {
dataMap.put(groupByValue, new MemoryResultSetRow(resultSet));
}
if (!aggregationMap.containsKey(groupByValue)) {
Map<AggregationSelectItem, AggregationUnit> map = Maps.toMap(selectStatement.getAggregationSelectItems(), new Function<AggregationSelectItem, AggregationUnit>() {
public AggregationUnit apply(final AggregationSelectItem input) {
return AggregationUnitFactory.create(input.getType());
}
});
aggregationMap.put(groupByValue, map);
}
}
private void aggregate(final ResultSet resultSet, final GroupByValue groupByValue, final Map<GroupByValue, Map<AggregationSelectItem, AggregationUnit>> aggregationMap) throws SQLException {
for (AggregationSelectItem each : selectStatement.getAggregationSelectItems()) {
List<Comparable<?>> values = new ArrayList<>(2);
if (each.getDerivedAggregationSelectItems().isEmpty()) {
values.add(getAggregationValue(resultSet, each));
} else {
for (AggregationSelectItem derived : each.getDerivedAggregationSelectItems()) {
values.add(getAggregationValue(resultSet, derived));
}
}
// groupByValue相等的行的聚合函数字段(each)归并
aggregationMap.get(groupByValue).get(each).merge(values);
}
}
next()方法
执行迭代器的next()方法。1
2
3
4
5
6
7
8
public boolean next() throws SQLException {
if (memoryResultSetRows.hasNext()) {
setCurrentResultSetRow(memoryResultSetRows.next());
return true;
}
return false;
}
Mysql分页归并(LimitDecoratorResultSetMerger)
LimitDecoratorResultSetMerger是个包装类,可以包装任意归并处理类。
LimitDecoratorResultSetMerger处理分页逻辑是在构造器时调用Offset次被包装的ResultSetMerger对象的next()跳过对应行数据;取数据时通过自身的next()方法限制获取的数据条数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35public final class LimitDecoratorResultSetMerger extends AbstractDecoratorResultSetMerger {
private final Limit limit;
private final boolean skipAll;
private int rowNumber;
public LimitDecoratorResultSetMerger(final ResultSetMerger resultSetMerger, final Limit limit) throws SQLException {
super(resultSetMerger);
this.limit = limit;
// 直接next() Offset次跳过
skipAll = skipOffset();
}
private boolean skipOffset() throws SQLException {
for (int i = 0; i < limit.getOffsetValue(); i++) {
if (!getResultSetMerger().next()) {
return true;
}
}
rowNumber = 0;
return false;
}
public boolean next() throws SQLException {
if (skipAll) {
return false;
}
if (limit.getRowCountValue() < 0) {
return getResultSetMerger().next();
}
// 限制总条数
return ++rowNumber <= limit.getRowCountValue() && getResultSetMerger().next();
}
}